
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Join
- 아티클스터디
- SQL
- 내일배움일지
- SQLD
- 데이터전처리
- 한줄for문
- 선형회귀
- ★
- 다중공선성
- 태블로
- AB테스트
- 내일배움캠프
- 이중for문
- Leetcode
- Set
- 프로그래머스
- python
- 시각화
- 데이터시각화
- 리스트
- f-string
- map
- Til
- 내배캠_학습기록
- 반복문
- 통계학
- DATE_SUB
- 가설검정
- Max
- Today
- Total
노력에는 지름길이 없으니까요
240807 아티클스터디 - SELECT로 SQL 쿼리를 시작하지 마라 본문
https://towardsdatascience.com/dont-start-your-sql-queries-with-select-clause-d30fa1b701f6
Don’t Start Your SQL Queries with the ‘Select’ Statement
Follow this right approach to write your SQL queries
towardsdatascience.com
팀원분이 추천해주신 아티클로 스터디 진행하기로 했다.
생각해보면 SQL 문제풀이를 할 때 항상 요구되는 컬럼명을 SELECT에 기재하고 시작하는 버릇이 있는데,
아티클을 읽으며 깨닫는 점이 있기를 바란다.
'이상적인' 쿼리 작성 순서는 SQL이 쿼리를 실행하는 방법과 일치해야 한다.
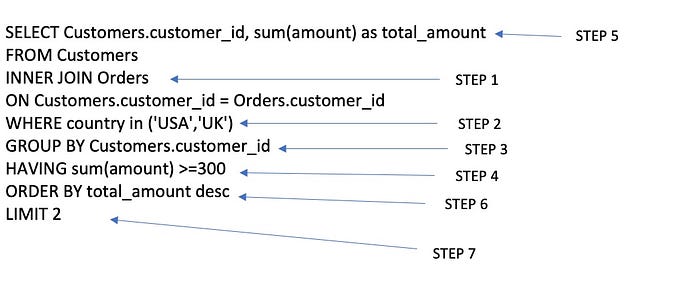
1. 항상 FROM/JOIN으로 시작
- FROM 절을 사용하여 테이블을 읽기
- 필요한 경우 JOIN 수행
어떤 테이블이 필요한지를 우선적으로 파악
JOIN 하기 전 필터가 필요한 부분이 있으면, ON으로 연결한 후 AND로 조건을 추가해두기
-- Filter happens before Join
FROM Customers
INNERJOIN Orders
ON Customers.customer_id = Orders.customer_id
AND country in ('USA','UK')
2. 그 다음 WHERE 절 기재
FROM Customers
INNERJOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE country in ('USA','UK') #그 다음 조건을 where절 처리
3. GROUP BY 사용
고객 ID를 기반으로 행을 그룹화 -> 그룹화 후 각 고객 ID는 출력에 하나의 행을 갖는다.
4. GROUP BY 다음 HAVING
집계된(aggregated) 행을 필터링 한다.
FROM Customers
INNERJOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE country in ('USA','UK')
GROUPBY Customers.customer_id
HAVINGsum(amount) >300
HAVING이 필요한 이유?
WHERE절은 GROUP BY 이전에 실행되고, HAVNING은 그 이후에 실행된다.
따라서 WHERE절은 집계된 데이터를 필터링할 수 없다.
5. SELECT 절 작성
select Customers.customer_id, sum(amount) as total_amount
FROM Customers
INNERJOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE country in ('USA','UK')
GROUPBY Customers.customer_id
HAVINGsum(amount) >300
6. ORDER BY는 SELECT 이후에 사용하자.
7. LIMIT 사용
보고싶은 행의 수를 제한
SELECT Customers.customer_id, sum(amount) as total_amount
FROM Customers
INNERJOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE country in ('USA','UK')
GROUP BY Customers.customer_id
HAVING sum(amount) >=300
ORDER BY total_amount desc
LIMIT 2
문제풀이를 할 때라면, 문제를 읽으면서 어떤 순서로 진행해야 할 지 파악하는 게 좋을 것 같다.
일반적인 경우 필요한 쿼리를 출력할만한 문제를 본인이 출제해서, 그 문제를 풀어가는 식으로 쿼리를 진행하면 되겠다는 생각이 들었다.
우선은 오늘 코드카타에서 건드렸던 문제로 응용해보기
https://leetcode.com/problems/customer-placing-the-largest-number-of-orders/

Write a solution to find the customer_number for the customer who has placed the largest number of orders.
The test cases are generated so that exactly one customer will have placed more orders than any other customer.
The result format is in the following example.
오더를 가장 많이한 사람은 몇 개를 했는지 출력하면 되는 문제.
오더를 가장 많이한 사람은 1명뿐이라는 게 명시되어 있고,
제시된 테이블은 단 하나뿐이기 때문에 1번은 쉽다.
1.
FROM Orders
2.
WHERE절이 필요 없는 것 같다고 생각되어 일단 넘어간다.
3.
customer_number별로 카운트를 세고 싶다.
FROM Orders
GROUP BY customer_number
4.
생략
5. 필요한 건 customer_number 자체값
SELECT customer_number
FROM Orders
GROUP BY customer_number
6.7.
내가 최댓값 항목을 출력하고 싶을 때 ORDER BY DESC LIMIT 1을 자주 사용해서
이번에도 그 방법을 써볼까 했다.
COUNT가 높은 순서대로 정렬을 해야하니 아래 구문이 추가된다.
SELECT customer_number
FROM Orders
GROUP BY customer_number
ORDER BY COUNT(customer_number)
LIMIT 1
예시가 쉽긴 했는데... 내일 코드카타에서 더 어려운 문제를 이 방식으로 한 번 풀어봐야겠다.
다른 데이터베이스에서도 순서가 같은지 확인해보았는데,
주요한 명령어는 다 같되, 언어마다 조금의 차이를 보인다.
SQL 실행순서
- FROM
- JOIN
- WHERE
- GROUP BY
- WITH ROLLUP (MySQL/MariaDB)
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT/OFFSET (MySQL/MariaDB/PostgreSQL)
- FETCH FIRST/NEXT (Oracle)
- OFFSET/FETCH (SQL Server)
'내일배움캠프 일지 > 아티클스터디' 카테고리의 다른 글
| 아티클스터디 240813 - A/B 테스트 제대로 이해하기 2, 3 (0) | 2024.08.13 |
|---|---|
| 240809 아티클스터디 - A/B 테스트 제대로 이해하기: 1. 테스트를 설계할 때 우리의 진짜 질문은? (0) | 2024.08.09 |
| 240719 아티클스터디 - 대기업 데이터분석가가 추천하는 데이터 분석 프로젝트 주제 (0) | 2024.07.19 |
| 240716 아티클스터디 - 데이터 기반 의사결정의 장점 (2) | 2024.07.16 |
| 240711 아티클스터디 - 데이터 속 거짓말 발견하기 (0) | 2024.07.11 |
