
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- Max
- 통계학
- 프로그래머스
- DATE_SUB
- f-string
- 데이터전처리
- 내일배움캠프
- Join
- 태블로
- Til
- 가설검정
- Set
- 내배캠_학습기록
- 한줄for문
- Leetcode
- 내일배움일지
- 시각화
- 반복문
- map
- 데이터시각화
- 선형회귀
- 이중for문
- 리스트
- python
- SQLD
- AB테스트
- 아티클스터디
- 다중공선성
- ★
- SQL
- Today
- Total
노력에는 지름길이 없으니까요
(미완) 로지스틱회귀 본문
로지스틱회귀
선형회귀를 차용하여 로지스틱이라는 방법을 가져와서 분류.
타이타닉 생존 분류 문제
https://www.kaggle.com/c/titanic/data
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
2 로지스틱회귀 이론
X가 연속형 변수이고, Y가 특정 값이 될 확률이라고 설정
P(Y = 생존(1))를 맞춘다. (0<=p<=1)
Y가 0,1 범주형인 경우 함수 적합

☑️ 로짓의 개념의 등장
위 S형태의 함수를 만들기 위해서 오즈비(Odds ratio)의 개념을 적용해 보겠습니다. 갑자기 왠 생소한 개념이라 생각하겠지만, 승산비라 불리는 오즈비는 실패확률 대비 성공확률로, 도박사들이 자주 쓰는 개념입니다. 예를 들어 도박이 성공할 확률이 80% 라면, 오즈비는 80%/20% = 4 예요. 다시 해석해보면 1번 실패하면 4번은 딴다는 소리입니다.

하지만 오즈비는 바로 쓸 수 없어요. P는 확률 값으로 0,1사이 값인데, P가 증가할수록 오즈비가 급격하게 증가하기 때문에 너무 확률이 급격하게 증가하고 선형성을 따르지 않게 됩니다. 따라서 로그를 씌워 이 부분을 좀 완화하기로 했어요.
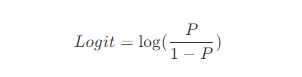
로그 -> 급발진을 멈춰주는... 완화시키는 역할을 해
오즈비와 확률의 관계 / 로짓과 확률의 관계
로짓의 그래프가 더 선형적인 그림을 나타내어 선형회귀의 기본식을 활용할 수 있게 됨
로지스틱”회귀”라고 불리는 이유가 이것
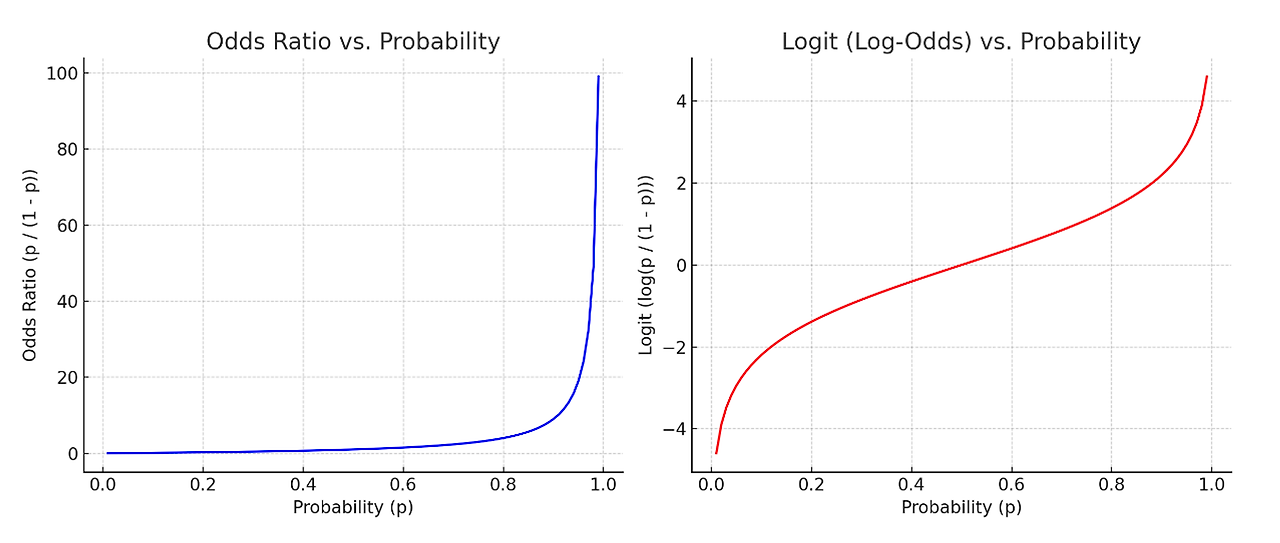
위 그래프의 확률 - 로짓 그래프 X-Y축을 교체
로지스틱 함수
로지스틱 함수는 시그모이드 함수 중 하나로 딥러닝에서 다시 활용되어요. 값을 계산하면 확률 도출 된다는 것만 기억하세요.


승객의 정보에 대해 로짓을 계산해보았을 때, 양극단으로 데이터를 보내는 경향이 있어서
분류 문제에 적용시키기 쉬운 편.
로짓의 장점은 어떤 값을 가져오더라도 반드시 특정 사건이 일어날 확률(Y값이 특정 값일 확률)이 0과 1안으로 들어오게 하는 특징을 가지게 됩니다.

로지스틱함수는 가중치 값을 안다면 X값이 주어졌을 때 해당 사건이 일어날 수 있는 P의 확률을 계산할 수 있게 됩니다. 이때, 확률 0.5를 기준으로 그보다 높으면 사건이 일어남(P(Y) = 1), 그렇지 않으면 사건이 일어나지 않음(P(Y) = 0)으로 판단하여 분류 예측에 사용합니다.
로지스틱 분류는 이진분류 (0,1)
다중분류(softmax)는 A, B, C ... 각 확률의 총합은 1
3. 분류 평가 지표
정확도의 한계
암 예측 모델: 무조건 환자가 음성(정상인)이라고 판정
100명의 환자 입실, 95명은 음성(정상), 5명은 양성(암 환자)
위에 따르면 암 예측 모델의 정확도는 95%
정확도는 매우 높은 것 같지만 실제로 양성(암 환자)는 하나도 못 맞췄어요. 이런 사기를 잘 걸러내기 위한 지표를 만들어봅시다 -> 데이터가 불균형한 상태에서는 문제를 잘 걸러내지 못함
혼동 행렬(confusion Matrix)

실제 값과 예측 값에 대한 모든 경우의 수를 표현하기 위한 2x2 행렬
실제(T,F) /예측(N,P)
표기법
실제와 예측이 같으면 True / 다르면 False
예측을 양성으로 했으면 Positive / 음성으로 했으면 Negative
해석
TP: 실제로 양성(암 환자)이면서 양성(암 환자) 올바르게 분류된 수
FP: 실제로 음성(정상인)이지만 양성(암 환자)로 잘못 분류된 수
FN: 실제로 양성(암 환자)이지만 음성(정상인)로 잘못 분류된 수
TN: 실제로 음성(정상인)이면서 음성(정상인)로 올바르게 분류된 수
지표
정밀도(Precision): 모델이 양성 1로 예측한 결과 중 실제 양성의 비율(모델의 관점)
행렬에서 중요한 값은 TP.
이 값을 가로 기준으로 보느냐 세로로 보느냐에 따라 다른 지표가 됨
지표
- 정밀도(Precision): 모델이 양성 1로 예측한 결과 중 실제 양성의 비율(모델의 관점)


2. 재현율(Recall): 실제 값이 양성인 데이터 중 모델이 양성으로 예측한 비율 (데이터의 관점)



실제 적용
TP: 실제로 양성(암 환자)이면서 양성(암 환자) 올바르게 분류된 수 → 0명
FP: 실제로 음성(정상인)이지만 양성(암 환자)로 잘못 분류된 수 → 0명
FN: 실제로 양성(암 환자)이지만 음성(정상인)이라고 분류된 수 → 5명
TN: 실제로 음성(정상인)이면서 음성(정상인)이라고 분류된 수 → 95명
정밀도는 정의되지 않음(divsion by zero), 재현율은 0
결과적으로 f1-score는 0
위처럼 정확도가 제 기능을 못하는 때는 분류에서 특히 Y값이 unbalance하지 못할 때 일어나요. 따라서 이를 위해서 Y 범주의 비율을 맞춰주거나 평가 지표를 f1 score을 사용함으로써 이를 보완한답니다.
