
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 가설검정
- Max
- 반복문
- 선형회귀
- Join
- 프로그래머스
- SQL
- DATE_SUB
- 리스트
- Leetcode
- 데이터전처리
- 데이터시각화
- 아티클스터디
- 다중공선성
- 내일배움캠프
- f-string
- python
- 통계학
- 시각화
- 이중for문
- 내일배움일지
- 내배캠_학습기록
- Set
- SQLD
- Til
- 태블로
- ★
- 한줄for문
- map
- AB테스트
Archives
- Today
- Total
노력에는 지름길이 없으니까요
240626 팀 프로젝트 진행 상황 본문
728x90
- 고객 데이터 분석 : 고객의 인구통계학적 정보, 거래 내역, 신용도 등을 분석하여 주요 고객 세그먼트를 식별합니다.
- 맞춤형 CRM 전략 수립: 각 고객 세그먼트의 특성과 요구를 분석하여 세그먼트별 맞춤형 전략을 수립합니다.
- 신용 관련 변수 분석 및 리스크 관리 : 고객의 신용 관련 변수 분석을 통해 신용 등급에 영향을 미치는 변수를 파악하고, 연체율이 높을 것으로 예상되는 고객을 관리하여 당사의 현금 유동성 리스크를 감소시킵니다.
Task
- 모든 그래프에 대해서 범주 색상은 통일 (B/G/S)
- 색상 변환할지 말지 결정
💡 프로젝트 흐름
파트1 ) 1~3
파트2) 4, 5
- 시작
- 목차 …
- 목적, 목표 … etc
- 전체 데이터 개요 제시
- 데이터 소개 → Bank Data
- bad와 good의 값 비교 (데이터 자체는 3군 모두 제시) ⇒ 개괄적 데이터 리스트화
- 컬럼 소개 (중심 컬럼 포함)
- 직업… → 고르게 분포되어 있었다…
-

아마도 데이터 자체가 균등하게 분포되도록 수집된 듯 하고, 값이 일정하지 않은 쪽은 전처리로 삭제된 듯 하다.
- 컬럼 소개 (중심 컬럼 포함)
나이 데이터 소개할 때는 연령대별로 bad, good 비교

- 그래프 예시

- 주제 대출 / 대출관련된 컬럼과 신용도가 bad인 그룹의 연관성을 분석하기로 했다
-
- Outstanding_Debt → 히스토그램중심 컬럼 소개 (데이터 자체는 3군 모두 제시) Delay_from_due_date, Num_of_Delayed_Payment는 같은 맥락이니 하나 제외해도 괜찮을 듯 (줄여야 한다면 Delay_from_due_date 남기는 걸로 → good, standard 쪽은 min값이
- Num_of_Loan → 누적 히스토그램, 박스 플롯
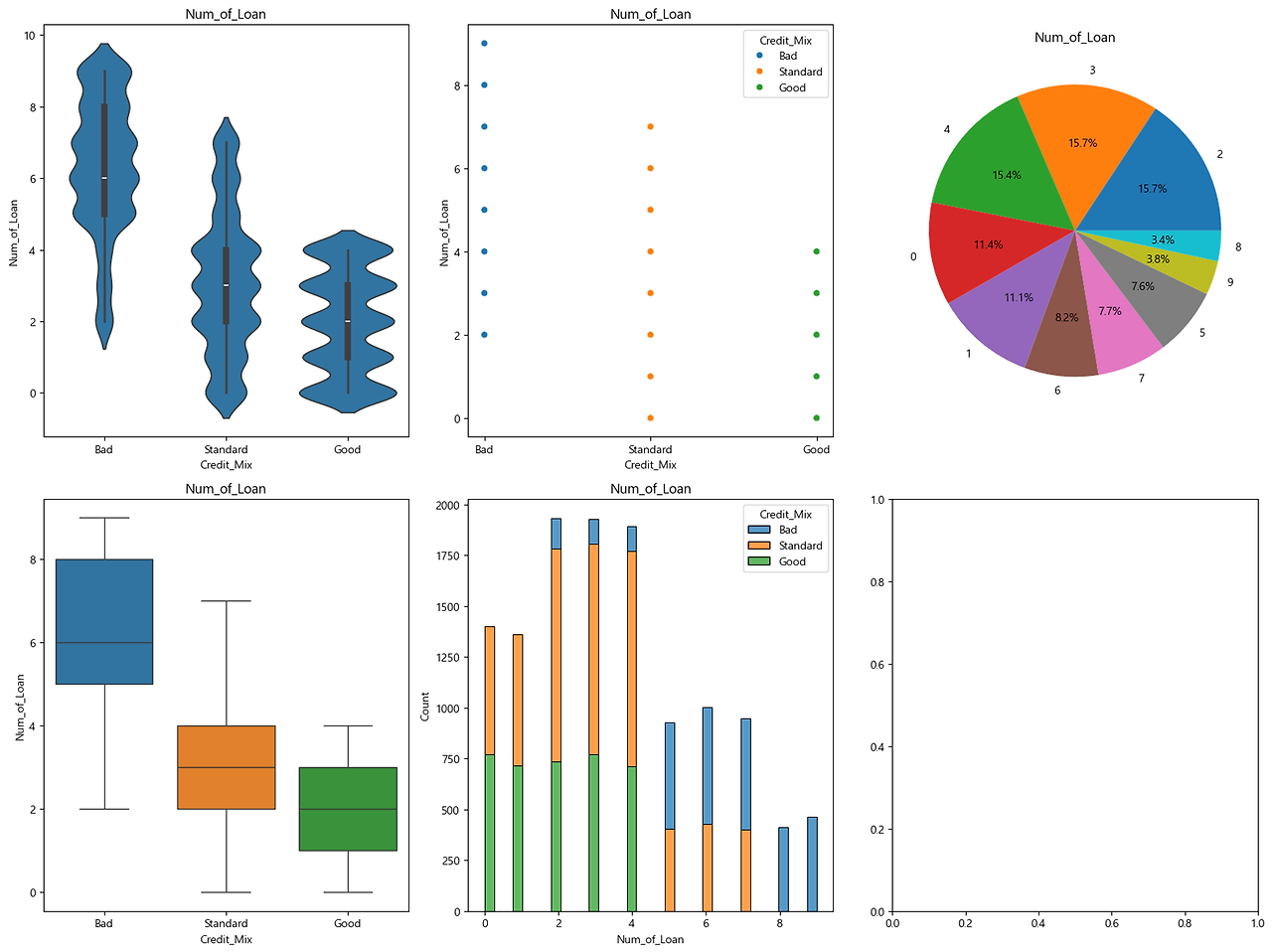
- 결과
- bad가 편차가 크다 (2-8)
- good은 편차가 적다…? 인원이 고르게 분포되어 있다.
- bad에는 0값이 없음, Standard, Good에는 0값이 있음
- -> 대출이 있는가 없는가?

- → 알 수 있었던 것 : 신용도가 Good인 그룹에서 대출을 아예 하지 않은 사람이 있었던 반면, Bad에는 없었다 … 등등
- Delay_from_due_date → 히스토그램

- bad에는 0값이 없음, Standard, Good에는 0값이 있음
- bad가 편차가 크다.
- good은 앞쪽에 몰려 있다.
- 신용도가 good인 일부 고객에 대한 …
- Num_of_Delayed_Payment 지연건수 → 박스플롯? kde_plot()

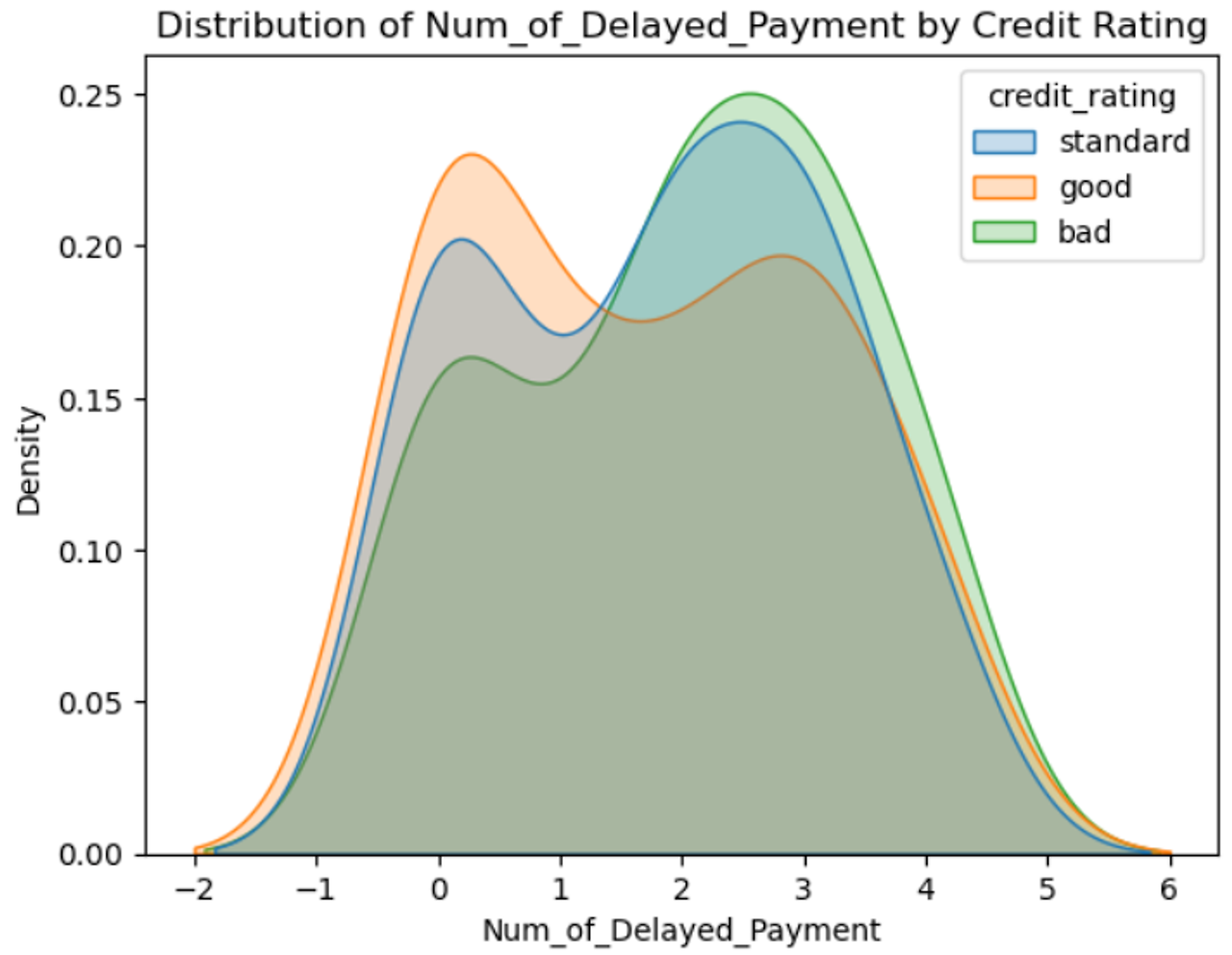
- 중위수 자체가 Bad가 높고 Good이 낮음
- good도 긴꼬리 분포를 띠고 있음.

- Outstanding_Debt → 히스토그램중심 컬럼 소개 (데이터 자체는 3군 모두 제시) Delay_from_due_date, Num_of_Delayed_Payment는 같은 맥락이니 하나 제외해도 괜찮을 듯 (줄여야 한다면 Delay_from_due_date 남기는 걸로 → good, standard 쪽은 min값이
-
-
- Total_EMI_per_month → 바이올린 플롯 혹은 산점도결과 :median 확인 결과 →
- 결론 :
- 월 할부금 이상치 확인 결과 → bad에 속한 인원들 최대 값이 standard와 good 인원의 값보다 현저히 낮음을 확인함 → 즉, standard와 good 인원이 더 높은 대출 할부금을 지불할 능력이 있고 지급하였기에 신용도가 높아진 것으로 추론해볼 수 있음

- Total_EMI_per_month → 바이올린 플롯 혹은 산점도결과 :median 확인 결과 →
bad에는 0값(지불한 채무) 없음, Standard, Good에는 0값이 있음
결과 :
결과 :
→ 이상치가 많은 것에 대해서 전처리를 할 필요가 있는지?
⇒ 필요한 내용 : 그래프 / GOOD, BAD 비교 (결과) / 여기서 알 수 있었던 것, 파악할 수 있는 것 (결론)
- bad인 사람들의 특성 구분을 위한 세그멘테이션
- 결론
TASK
- 나이대 관련 분포도 그래프 그리기
- → 가장 많은 비중을 차지하는 연령별에 대한 분석을 진행
- → 어느 연령대를 공략해야 하는가에 대한 인사이트 정리
- Credit_Mix에 따른 나이대 분포

- 결과
- 나이대별로 전체를 비교해 보니 10대와 50대가 각각 9.6%, 9.3%로 비슷하며,
- 대부분 20-40대가 높은 비율을 차지함 (각 28.9%, 29.2%, 23.0%)

- 결과
- 신용도가 Good인 10대가 인구비율의 평균보다 적다. (2.8% < 9.1%)
- 신용도가 Good인 50대가 인구비율의 평균보다 많다. (21.7% > 9.3%)
Credit_Mix(신용도)가 Standard

- 결론
- 히스토그램과 분포값이 가장 유사하다.
- 결과
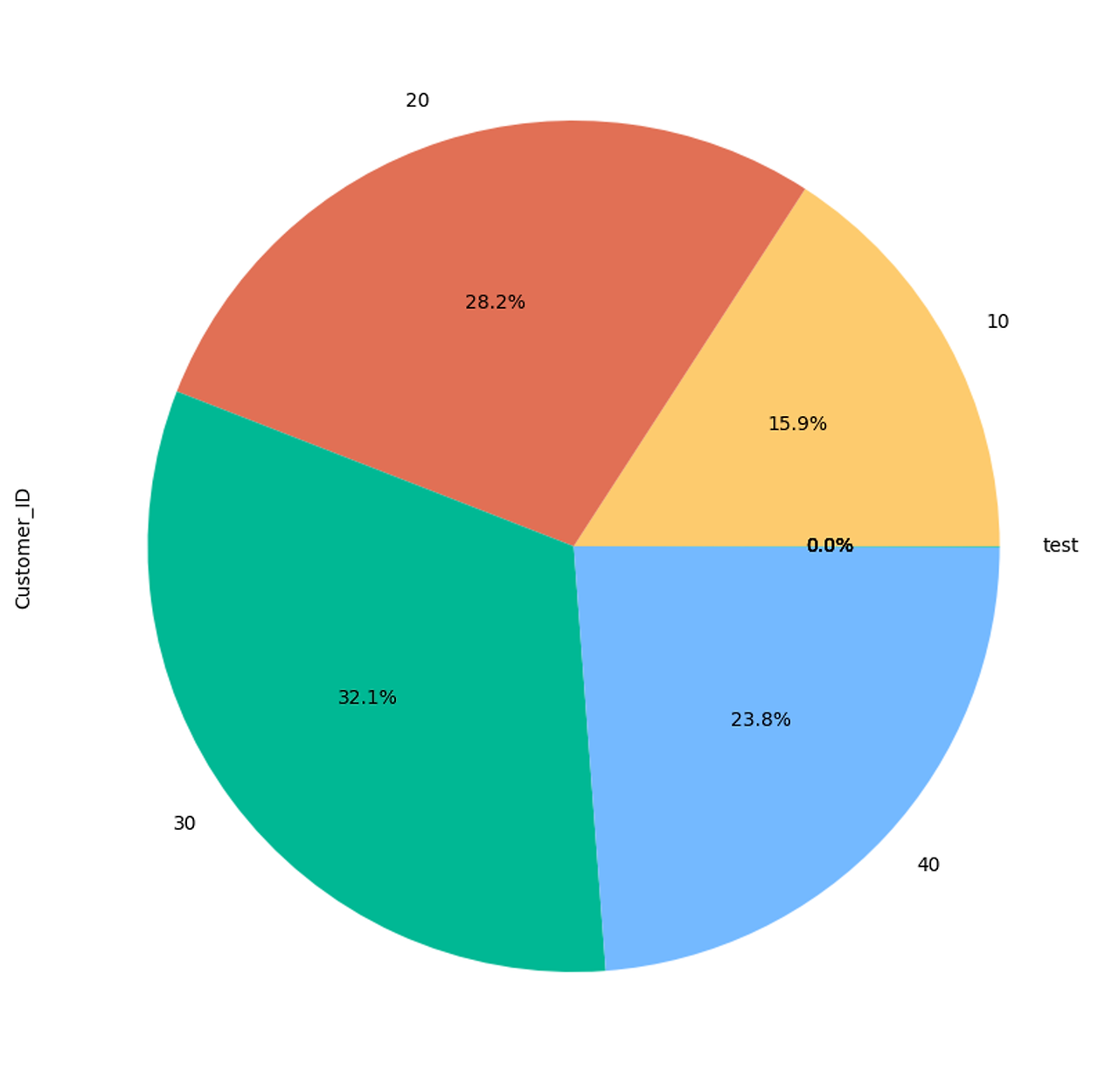
- 신용도가 Bad인 50대 이상의 비율이 0에 수렴…
- 신용도가 Bad인 10대가 인구비율의 평균보다 많다. (15.9% > 9.1%)
- 신용도가 Bad인 30대가 인구비율의 평균보다 많다. (32.1% > 29.2%)
- 외국임을 고려해도 나이대가 10, 20대인 사회초년생이 신용도를 쌓는 것은 어려운 일이다. (PT에 해당 데이터 국가의 신용도 관련 설명을 짧게라도 넣는 것이 중요할 것 같음)
- 20, 30대들의 비율이 높은 이유는 이들은 보통 사회에 들어가고 어느 정도의 시간이 지났기에 사업이나 결혼 등을 하기 때문임 (추론)
Credit_Mix(신용도)가 Bad
- 모든 연속형 데이터에 대해서 그래프 생성하기
- 박스 플롯
- 히스토그램 (3가지 범주 겹쳐서 색상 차이 둔 히스토그램 작성법 조사!)
- 파이 그래프
- 산점도
- 바이올린 플롯
- → 그래프 생성
- 직업 분포도 파이 그래프
히스토그램
색상 관련 조사
- 직관적으로 사람들이 생각하는 청신호, 적신호 이미지를 따라갈 것인가 → 가장 실패확률이 적고 이미지 파악이 쉬움
- 팀 내에서 지정한 개별적인 색상을 쓸 것인가 → 채도나 명도 구분에 따라서 강조점을 만들 수 있음
아래 링크에서 선별했습니다! 시간 남으시는 분들은 다른 예시 골라서 올려주셔도 돼요!예시 가져와보았고, 어떤 게 괜찮아 보이는지 말씀해주시면 좋을 것 같아요!
- My collection of color palettes on Color Hunt
- Bad, Standard, Good
728x90
반응형
'내일배움캠프 일지 > 팀 프로젝트' 카테고리의 다른 글
| 기초 팀프로젝트(1차) 피드백 정리 (0) | 2024.07.31 |
|---|---|
| 240625 팀 프로젝트 진행 상황 (0) | 2024.07.25 |